
Nov 15th 2013, 13:00, by Ars Staff
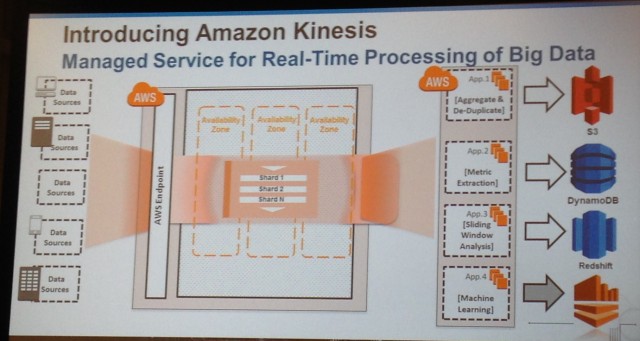
A slide from Amazon's Re:Invent conference describes Kinesis' architecture.
Jason Levitt
Kinesis adds to Amazon’s existing set of big data services, notably Elastic Map Reduce, a hosted Hadoop solution; Redshift, a data warehouse solution; DynamoDB, a NoSQL store; S3, an object store; and Glacier, Amazon’s archival service. While it's not yet ready for prime time, Amazon is offering customers the opportunity to sign up for a limited preview of Kinesis now.
Kinesis is relatively late on the real-time stream scene. Multiple solutions for dealing with large volumes of streaming data already have some foothold, including the open source Storm and Apache's S4 projects, as well as the commercial offerings such as IBM InfoSphere Streams. But while all of these solutions can process huge amounts of streaming data, Amazon’s hosted model is particularly convenient for businesses that want a managed solution and don't mind in investing in some development work but would rather not invest in any infrastructure.
No comments:
Post a Comment